Abstract
Depth Anything 的问题:处理视频时遭受时间不一致性(temporal inconsistency)。
作者提出了Video Depth Anything,能够对长视频高效地生成高质量持续的深度估计。
Video Depth Anything 基于 Depth Anything v2 ,将它的 head 替换为高效的 spatial-temporal
head。
作者设计了直接且高效的时间一致性损失函数,通过约束时间深度梯度,消除了额外的几何先验的需求。
Introduction
特别地,作者先设计了轻量的 spatial-temporal head (STH) 去替换 DPT head ,然后使得时间信息能够交流。STH包含四个时间注意力层 (temporal attention layers) , 应用在每个空间位置的时间维度。只在 head 引入 时间注意力防止了已经学习过的表示(representation)被有限的视频数据破坏。
接着,作者提出了时间梯度匹配损失函数,去约束沿着时间维度的深度估计梯度,匹配从ground truth 计算得到的值。这个损失函数同时用尺度平移不变损失和空间梯度匹配损失优化了。
为了能够做长视频的推断,作者开发了新的分段处理策略(segment-wise processing strategy)。每一个新的段都用 8 个重叠的帧和之前视频片段的两个关键帧连接,共形成 32 帧。然后,为了保证平滑性,重叠的帧将逐步在两个连续的窗口插值。
Related Work
略
Method
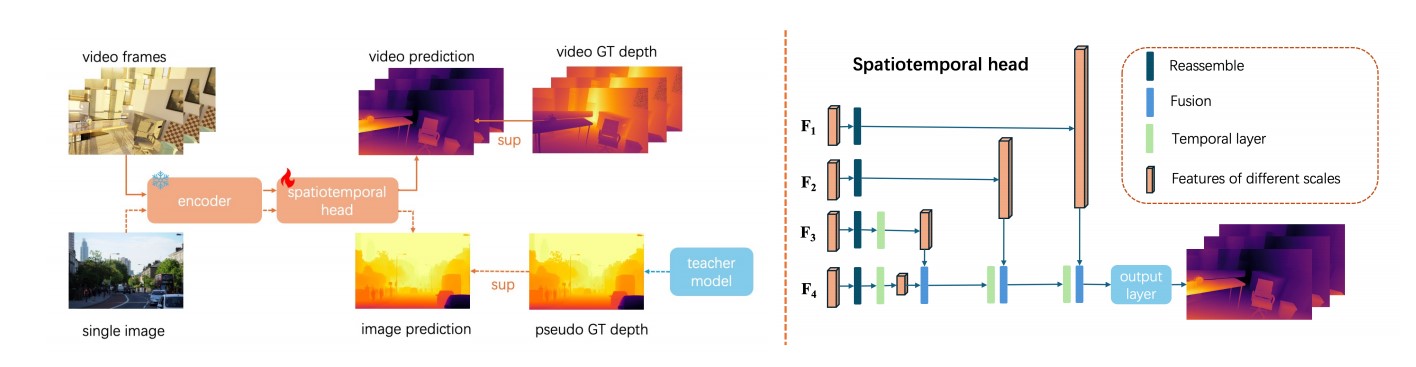
Architecture
由于缺少足够的视频资源,作者从预训练的 Depth Anything v2 开始,采用共同训练策略,同时用图像和视频数据。
Depth Anything Encoder
用了 Depth Anything Encoder 作为模型的 encoder。为了减少训练损耗和保护训练好的特征,这个encoder要冻结参数。
为了用image encoder提取视频帧里的特征,作者将视频片段中的时间维度折叠到批次(batch)维度中。
输入:$ {X} \in \mathbb{R}^{(B \times N) \times C \times H \times W} $ ,B为batch大小,N为视频片段帧数,C为通道数。
通过encoder后得到中间特征图 $ {F_{i}} \in \mathbb{R}^{(B \times N) \times (\frac{H}{p} \times \frac{W}{p}) \times C_i} $ ,p为encoder的patch大小。
image encoder忽略了两帧之间时间信息,需要spatiotemporal head。
Spatiotemporal Head(STH)
STH在DPT(Vision transformers for dense prediction) head的基础上多插入了一个时间层来捕获时间信息。一个时间层包含多头自注意力模型和前馈网络(feed-forward network)。当时间层输入一个特征 $ {F_{i}} $ ,时间维度N孤立,自注意力只在时间维度进行,以促进时间特征的交互。为了捕捉不同帧之间的时序位置关系,我们利用绝对位置嵌入来编码视频序列中的时序位置信息。
STH在 $ {F_i} $ 均匀采样了4个特征图(包含最终特征,记为 $ {F_4} $)作为输入,预测深度图 $ {D} \in \mathbb{R}^{H \times W} $ 。选中的 $ {F_i} $ 输入reassemble layer生成特征金字塔。然后,特征从低分辨率到高分辨率通过fusion layer进行融合。reassemble layer和fusion layer由DPT提出。最终融合得到的高分辨率特征图通过输出层生成深度图 $ {D} $ 。为了减少计算量,作者在一些特征分辨率低的地方插入了temporal layer。
Temporal Gradient Matching Loss
OPW(Optical Flow Based Warping) loss
为了约束时间一致性,之前的视频模型假定相邻帧对应位置的深度一致,通过光流检验。
对于两个深度预测结果, $ p_{i}, p_{i + 1} $ ,根据从光流推出的扭曲关系, $ p_{i + 1} $ 被扭曲成 $ \hat{p}_{i} $ ,则损失函数为
N为视频窗口长度, $ ||\cdot || $ 为 $ l1 $ 距离。
OPW的严重问题:相邻帧对应点的深度不是不变的。
作者提出新的方式。
Temporal gradient matching loss(TGM)
我们假设相邻预测帧中对应点的深度变化应与在ground truth中观察到的变化保持一致。
这里d, g都是预测值和ground truth缩放和平移后的版本。
然而,生成光流会带来额外的开销。
事实上,不需要用光流得到对应点来使用,可以直接用相邻帧同一坐标系的深度计算损失。假设是相邻帧同一个 图像位置 的深度应当与ground truth一致。这个过程和在时间维度计算梯度一致。
实践中,参考的点在ground truth里在相邻帧深度变化较小,$ |g_{i + 1} - g_i| < 0.05 $ ,避免边缘、动态物体等因素对深度图产生突然变化使得训练不稳定。
总损失
$ \mathcal{L}_{ssi} $ 是尺度和平移不变损失函数(见MiDaS)。$ \alpha, \beta $ 用于平衡时空一致性和单帧的空间结构。
Inference strategy for super-long sequence
提出了关键帧参考(key-frame referencing),继承之前预测的尺度和平移信息,将插值重叠保证平滑变化。
key-frame referencing
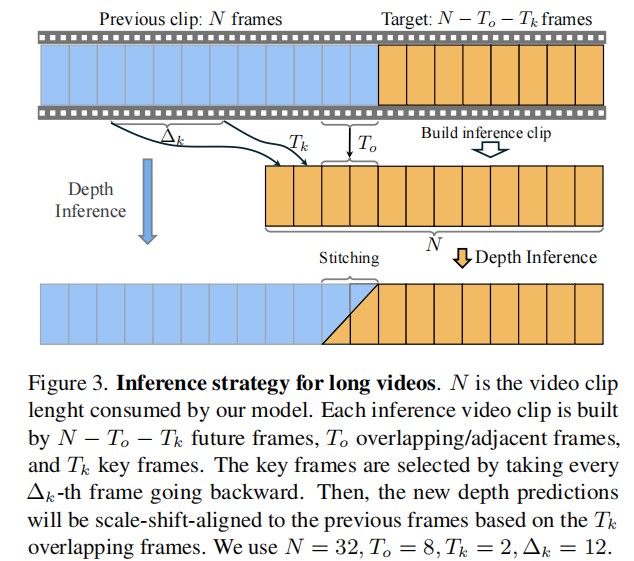
将一段视频分成三段:$ N - T_o - T_k $ 张未来的帧,$ T_o $ 张重叠的帧(之前的帧),$ T_k $ 张关键帧(之前的帧)。关键帧从之前的帧里子采样,间隔大小为 $ \Delta k $ 。这种方法将早期窗口的内容最小化计算量,融入当前窗口。根据实验结果,这种简单的策略可以显著减少累积的尺度漂移,特别是对于长视频。
Depth clip stitching
相邻窗口的 $ T_o $ 张重叠的帧对避免深度图像闪烁很重要。
通过共享部分帧特征,连续窗口间的尺度和平移将更加相似。
重叠帧的深度预测是通过在两个片段之间进行插值来更新的。
假设之前的段第 $ o_i $ 张重叠帧的深度为 $ {D}_{o_i} ^{pre} $ ,当前的段深度为 $ {D}_{o_i}^{cur} $ ,则最终深度为 $ {D}_{o_i} = {D}_{o_i}^{pre} \cdot w_i + {D}_{o_i}^{cur} \cdot (1 - w_i) $ , $ w_i $ 大小从1到0、长度为 $ T_o $ 的线性衰减函数。
Experiments
略
Conclusion
略